
Meta ще раз підтвердила, що не збирається поступатись Microsoft і Google у ШІ-перегонах. Компанія відкрила доступ до ImageBind — штучного інтелекту, який може імітувати людське сприйняття. Модель здатна пов’язувати текст, зображення, відео, аудіо, 3D-вимірювання, дані про температуру й рух. Розробка може суттєво скоротити розрив між людиною і машиною в плані цілісного навчання й створення складного контенту з різних типів даних. Докладніше про нову модель ШІ від Марка Цукерберга — у матеріалі “Ми-Україна”.
Чому ImageBind є проривом у розробці штучного інтелекту
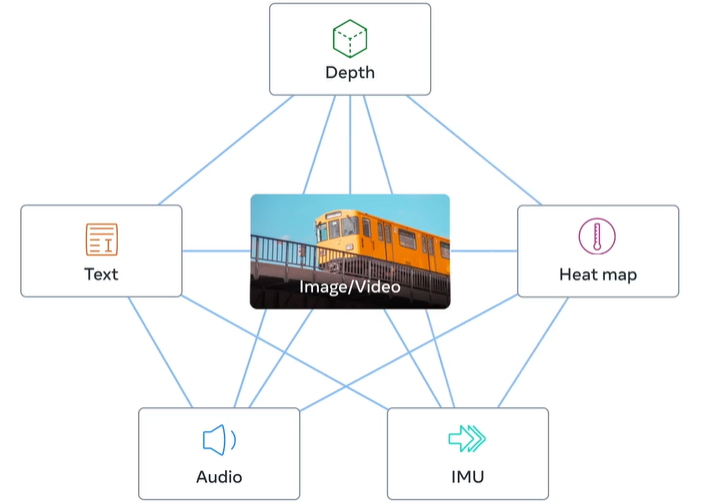
ImageBind є частиною проєкту Meta зі створення мультимодальних систем, здатних навчатися на різних типах даних. Ця модель не лише розуміє дані, а й здатна пов'язати його з іншими функціями. Наприклад, визначати звук, форму, температуру й те, як рухаються об'єкти на фотографії.
Компанія стверджує, що ImageBind перевершує інші моделі, навчені для певної модальності. На відміну від генеративних ШІ, таких як ChatGPT або Midjourney, ШІ від Meta пов'язує шість типів даних у багатовимірному індексі. Користувачі зможуть використовувати будь-який з них як метод введення або перехресно посилатися на них.
Однією з особливостей ImageBind є те, що він використовує концепцію навчання, аналогічну людській. Коли люди поглинають інформацію зі світу, ми використовуємо кілька почуттів. Ми здатні генерувати сенсорні відчуття під час перегляду зображення. Наприклад, дивлячись на фотографію Ferrari, ви можете думати про звук двигуна або швидкість, з якою рухається авто.
Якщо ви стоїте в інтенсивному середовищі на кшталт людної вулиці, ваш мозок поглинає образи, звуки та інші сенсорні відчуття, щоб вивести інформацію про автомобілі та пішоходи, високі будівлі, погоду й багато іншого. Адже обробка інформації є наслідком еволюції та запорукою виживання. Чим краще ми обізнані про своє оточення, тим ефективніше можемо уникнути небезпеки й адаптуватися до навколишнього середовища. І тим комфортнішим буде наше життя.
У міру того, як комп'ютери наближаються до імітації мультисенсорних зв'язків, вони можуть використовувати їх для створення повністю реалізованих сцен, заснованих на обмежених фрагментах даних.
Можна використати Midjourney для створення котика у костюмі Гаррі Поттера, що балансує на летючий мітлі й отримати відносно реалістичне зображення. Але мультимодальний інструмент ШІ, такий як ImageBind, може створити відео папуги з відповідними звуками в деталізованій кімнаті, відобразити температуру в приміщенні й точне місцеперебування всіх елементів сцени.
Особливість ImageBind у тому, що він створює “спільну мову” для різних типів даних, не вимагаючи прикладів, що містять усі ці дані. Такі набори модальностей було б дорого, або навіть неможливо отримати.
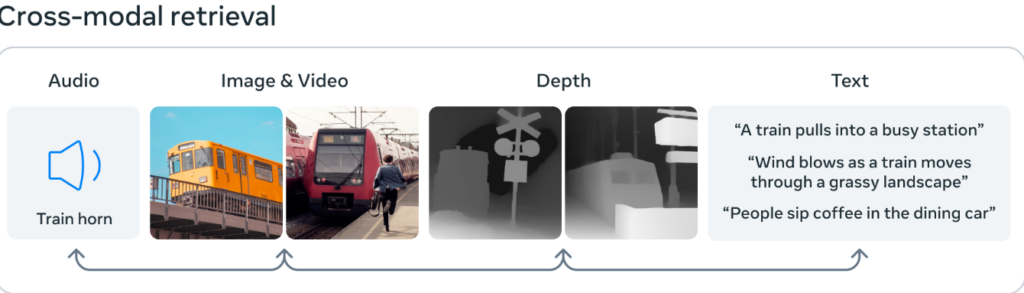
ImageBind використовує неструктуровані дані для інтеграції чотирьох додаткових (окрім тексту й зображень) модальностей — аудіо, глибина, теплова та інерційні вимірювання (IMU). ШІ може вчитися на природних зв'язках між типами даних без необхідності використання спеціальних вказівок.
Розробники також пояснюють принцип успішної роботи ImageBind. Річ у тім, що зображення часто можна комбінувати з іншими даних та використовувати як місток між ними. Наприклад, зображення й текст часто з'являються в інтернеті разом, тому модель може вивчити взаємозв'язок між ними.
Так само дані про рух з камер з датчиками IMU можна зіставити з відповідними відеоданими. Використовуючи ці природні пари, ImageBind створює загальний простір для навчання, який дозволяє ШІ краще розуміти та працювати з кількома модальностями.
"ImageBind показує, що даних, пов'язаних із зображеннями, достатньо, щоб пов'язати докупи ці шість модальностей. Модель може інтерпретувати контент більш цілісно, дозволяючи різним модальностям "спілкуватися" одне з одним і знаходити зв'язки. Наприклад, ImageBind може зв'язати звук і текст, не бачачи їх разом. Це дозволить іншим моделям "розуміти" нові модальності без будь-якого ресурсомісткого навчання", — пишуть розробники у свохму блозі.
У Meta також зазначають, що у майбутні моделі можна буде додати інший потік сенсорних даних. Йдеться про дотик, мовлення, нюх та сигнали мозку (томографія). Розробники впевнені, що дослідження "наближає машини на один крок до здатності людей вчитися одночасно, цілісно й з різних форм інформації".
Як можна використовувати ImageBind

ImageBind наближає реальність метавсесвіту, адже окрім тексту модель ШІ розуміє аудіо, візуальні дані, дані датчиків руху, теплові та глибинні дані. У Meta вважають, це робить його універсальним будівельним блоком для генеративних моделей ШІ. Отже, в яких сферах ця модель може бути корисною:
- ImageBind може бути основою для моделей, які об'єднують різні типи даних для кращого проєктування віртуальної реальності. (VR). Або доповнюють реальність контекстно-залежними цифровими даними (AR). Як відомо, VR і AR — дві ключові технології в довгостроковому баченні Метавсесвіту. Уявіть собі гарнітуру, яка може на льоту створювати повністю реалізовані 3D-сцени (зі звуком, рухом тощо);
- Розробники віртуальних ігор могли б використовувати ШІ типу ImageBind, щоб спростити процес візуального проєктування. А дизайнери могли б створювати анімовані короткометражки на основі лише зображення та звукового файлу;
- Творці контенту можуть створювати відео з реалістичними звуковими складовими й рухом, ґрунтуючись лише на тексті, зображенні чи аудіо даних;
- ImageBind у перспективі може допомогти людям із фізичними вадами. Модель теоретично можна задіяти у створенні мультимедійних описів у реальному часі, щоб допомогти людям із порушеннями зору чи слуху краще сприймати своє оточення;
- Модель може допомогти згенерувати відповідні фонові звуки або передбачити дані глибини на основі фотографії. Це може бути корисним у геодезії та інженерних роботах;
- ImageBind розширює можливості візуального і саунд-дизайну. Можна буде створити звукову доріжку для відео про море, яке ви записали під час відпустки. Або віртуальну подорож на човні, з усіма необхідними елементами, що зробить її максимально захопливою й реалістичною. Ви не тільки опинитесь на кораблі з шумом хвиль на задньому плані, але й відчуватимете розгойдування палуби під ногами та прохолодний океанський бриз.
І хоча перші результати виглядають перспективно, мине ще багато часу, перш ніж ми побачимо програми в стилі ChatGPT, що використовують ImageBind. Однак це не завадило Meta розповісти про можливості, які з'являться у людей під час його використання.
Наразі ж модель являє собою дослідницький проєкт, який не має безпосереднього застосування. Проте наявна версія ImageBind вказує на майбутнє генеративного ШІ, який зможе створювати захопливий мультисенсорний досвід. Також це свідчить про те, що розробники не зрадили принципу "відкритого вихідного коду. Як і у випадку з моделлю SAM, Meta продовжує ділитися дослідженнями у сфері ШІ, тоді як конкуренти з OpenAI та Google стають все більш закритими.
Зокрема творці ChatGPT упевнені, що ця практика відкритого коду шкідлива для розробників, тому що конкуренти можуть копіювати їхню роботу. Також це може бути потенційно небезпечним, бо дозволяє зловмисникам використовувати у своїх інтересах сучасні моделі ШІ.
Водночас прихильники підходу Google зазначають, що відкритий вихідний код дозволяє третім сторонам ретельно перевіряти системи на наявність помилок та усувати деякі з їхніх недоліків.
Нагадаємо, "Ми-Україна" зробив підбірку з 10 нейромереж для швидкого створення унікальних текстів та зображень.













